1 Introduction¶
This document covers core technologies and interactions between services, APIs, and applications interacting with the LSST Science Platform. The authentication use cases covered in this cover interactive users who are primarily interacting with the LSP in the following ways:
- Logged into the notebook aspect
- Logged into the portal aspect
- From a local terminal, exercising the API aspect from third party libraries or applications
For the users in question, we make a few assumptions about use of the LSP in this context:
- Users include LSST staff, and scientists that are members of science collaborations.
- Users already have an NCSA account through some mechanism. If they wish use federated credentials, the assumption is that their federated credentials have been associated with their NCSA account.
- Users are active, continuously or intermittently, over the course of an extended work day. Interactions will typically last several hours, though the system should be prepared for interactions lasting up to 24 hours.
- At the start of an interaction with the LSP system, users do not know which types of data they will access. Users do know which services they will access.
2 Basic Concepts¶
We define users and groups within this document, as well as minimal requirements from the IAM system as needed by the LSP, and likely the broader Data Management System. It’s expected further definition of the IAM system will be available in the future in a change controlled document.
2.1 User¶
A user is minimally identified by either a UNIX ID number (UID) and a user name. A service MUST be able to lookup a UID if it has a user name, or a user name if it has a UID.
2.1.1 Real Accounts¶
A user account identifying a specific person is a real account. All LSST users in the US and Chilean DACs have an LSST account. An LSST account is also the same account as an NCSA UNIX account.
2.2 Groups¶
A user is a member of one or more groups. All groups defined for a given user are owned exclusively by that user. All groups a user creates MUST follow the group naming conventions outlined by the LSST Chief Security Officer. A core set of groups do not belong to a specific user. These are defined and managed by the LSST system administrators.
The IAM system SHOULD disallow group names that are not representable as UNIX group names or database role names within the Data Management System. This implies a 32 character limit, as limited by Red Hat Linux.
Note
Before Oracle 12.2, there’s a limit of 30 characters on role names.
All users MUST be a member and the only member of a user-private group. The group name should be the name of the user. This follows the Red Hat feature called User Private Groups.
Some systems, to which Groups may be synced to, may not allow assignment of permissions directly to users, only groups. If this is the case, then a user can assign permissions to the user private group. This would enable another user to extend access to a resource by assigning a read permission to the user’s group, for example.
Group membership MUST be discoverable through at least an LDAP service provided by the IAM system. Additional services for querying group membership MAY be implemented.
2.2.1 User and Groups Synchronization¶
When necessary, the IAM system SHOULD create users and groups in underlying systems; synchronizing membership accordingly. The synchronization SHOULD finish in under an hour, and MUST finish within 24 hours.
In databases, groups should be represented as roles.
The assignment of privileges on resources according to users and groups is out of scope for this document.
2.2.2 Caching Group Information¶
Clients querying a group membership service SHOULD cache results. Results SHOULD be cached with a TTL for no less than 30 seconds and no longer than 1 hour. A 5 minute TTL is recommended.
Users and services should be made aware of the caching TTL as well as potential latencies due to user and groups synchronization. It may take up to 2 hours for groups to be synchronized and caches invalidated.
If group information is encoded in a token, users MUST be informed to destroy the token through some form of logout mechanism. Single Logout is out of scope for this document.
2.2.3 Privacy and File Sharing¶
Note
This section is informational
Through the use of sticky bits, umasks, and user-private groups, it will be possible to build a system that can both preserve privacy, by setting sticky bits on user-private directories for the user’s user-private group, as well as preserve access on directories that are intended to be shared, such as those owned by a Science Collaboration.
2.3 Roles¶
Note
This section is informational
There’s currently no concept of roles in the existing IAM system for NCSA. A system that represents roles must also have permissions associated with roles. As such, Roles and are generally out of scope for this document, but they are mentioned for informational purposes.
It’s possible that roles may be implemented group membership. For example, the portal web
application may rely on having the groups lsst_int_portal_usdac_user,
lsst_int_portal_pdac_user, and lsst_int_portal_admin defined. In this example, these groups
are effectively roles. The portal application can limit what a user can do based on membership
in these groups. The portal may also manage the roles in a user session context; a user may be
allowed to be an admin by being a member of the admin group, but the user may assume the user role
by default, with forced re-authentication being necessary to assume the admin role.
2.4 Authentication¶
Authentication in LSST is the act of associating a user with their LSST account.
Authentication by a real user is handled by the IAM system. All authentication for LSP services are handled through the OAuth 2.0 Protocol by the IAM system. Normally this will be through the OpenID Connect layer.
Authentication for a shared account is out of scope for this document. It is expected that users may be members of groups that are owned by shared accounts, but they will always authenticate as themselves.
Authentication using means such as kerberos is out of scope of this document.
2.4.1 identity.lsst.org - Account Management¶
All accounts can be managed through identity.lsst.org. This will
include profile information about the user, as well as group management. Users may need to interact
with an LSST administrator in order to be granted the ability to create groups. This can be done by
emailing lsst-account _at_ ncsa.illinois.edu (and CC lsst-sysadmins _at_ lsst.org).
2.4.2 Federated Identity and LSST Accounts¶
In order to improve security and convenience for users, users may associate eligible accounts with their LSST account, enabling them to delegate to third parties authenticators. This associaton is called Federated Identity, which allows you to authenticate to LSST services using the associated accounts. CILogon is used to determine eligible authenticators for federated identity; the list typically includes accounts from the InCommon federation, as well as OAuth accounts from services such as Google and Github. Association of accounts from third party authenticators to the user’s LSST account is configured through the identity.lsst.org account management portal. Once an account is associated, a user can login using credentials and authentication services from their associated accounts.
After a successful federated authentication from the associated account, the CILogon service MUST produce the equivalent authentication information to that of a successful authentication of an LSST account.
2.5 Authorization Methods¶
Authorization in LSST helps determine what acts a user may perform in a given system.
2.5.1 Service Access Authorization¶
LSP services MAY limit access by users at the service level. The IAM system MUST return service access capabilities in the form of claims in tokens for services.
In these cases, a service needs to acquire a list of groups associated with a user, either as claims in a token, or through a membership query to a service.
See also
2.5.2 Data Access Authorization¶
Low-Level systems SHOULD be relied upon to authorize access to data. This includes:
- Disk Storage, such as NFS, GPFS;
- Databases, such as Oracle or Qserv
2.5.3 Capabilities-based Authorization¶
Note
This section is informational
We expect some form of capabilities-based authorization will be useful for the Data Management System in the future. This section is an overview of capabilities-based authorization and requirements to implement such a system.
Capabilties-based security system is based on the object-capability security model.
A capabilities-based system, in the context of LSST DM system, would rely on:
- A definition of resources across the LSST DM system to which you can assign access rights to; such as dataset collections (butler repos), database tables, services.
- A reference to a resource or set of resources; such as a token, which the system can validate and enforce access control
- A definition of operations to be performed on the resource; such as
read,write, andexecute, for example.
Together, the reference and operation can be included in a message and will represent a capability. In order for the system to be secure, the message MUST be unforgeable. This is implemented through a cryptographic signature.
For the issuance of the capabilities, the following are required:
- A method of determining the set of those capabilities for a given user or use case; and
- A system which either implements that method, which issues the unforgeable message (a token or certificate); or
- A system that is notified notified by another system implementing the method;
2.5.3.1 Authorization¶
Low-level systems, including disk storage (NFS, GPFS, S3/Swift/Ceph) and databases (Oracle, MySQL), do not have a way of enforcing capabilities-based authorizations. As such, to integrate a security system with capabilities, it’s required to have a service in front of those systems which can process the messages.
To process a request with a capabilities message, a service MUST:
- Agree to the definition of resources issued in the message, mapping them to the system the system (or underlying system) manages
- Agree to the definition of operations in the message; mapping them to the operations the system (or underlying system) implements
- Examine the request and verify ALL resource and operation pairs a request may need are represented in the message.
For the LSP, we have not finished defining the resources of the message, though we expect those
resources will correspond roughly to services; we expect operations will be either read,
write, or execute in the context of LSP; and we expect a service will largely control
access to itself, and, transitively, the data served by that service. The resources, operations,
and services currently identified are in the data and service
classifications section below.
2.6 Data and Service Classifications¶
Note
This section is informational
Warning
This section is subject to change
These classifications are loosely based on LPM-122 classifications, LDM-542, and LSE-163. Work is being performed to clarify the classifications of data and services together.
| Resources | Operations Allowable | Risk Level | Services |
|---|---|---|---|
| Image Access | read | medium | Imgserv/SODA (Butler via POSIX), POSIX |
| Image Access (Metadata) | read | low | SIA, TAP |
| Table Access (DR, Alerts) | read | medium | TAP, QServ (Only through TAP) |
| Table Access (Transformed EFD) | read | low | TAP, Consolidated (Notebook via SQL Client) |
| Table Access (User and Shared) | read, write | high | TAP, Consolidated (Notebook via SQL Client) |
| User Query History | read | high | TAP |
| File/Workspace Access | read | medium | WebDAV, VOSpace, POSIX, Notebook (via POSIX) |
| File/Workspace Access (User/Shared) | read, write | high | WebDAV, VOSpace, POSIX, Notebook (via POSIX) |
| Portal | execute | high | Portal |
| Notebook | execute | high | Notebook |
3 Tokens¶
Broadly speaking, there are two main types of tokens in the LSST DM system. Tokens whose primary use are for identity, which are issued from CILogon, and tokens whose primary use are for checking capabilities. Identity tokens are roughly equivalent to X.509 certificates; they include information about the user identity, including the username for the LSST account and/or the UNIX UID, and group memberships, in addition to a cryptographic signature for verifying the token integrity using public key encryption.
Capability tokens, in the LSST DM system, will minimally also include the UNIX UID and/or username for the LSST account, as well as a list of capabilities for the token.
Due to the additional infrastructure and definitions required for implementing capabilities-based authorization, we intend to implement authentication and authorization in the LSST DM system in two phases.
3.1 Phased Approach to Authorization¶
Phase 1 is authorization through identity. LSP services will rely on identity from identity tokens, including UID and group membership, to authorize access to services; services, notably the LSP API aspect, will implement impersonation in some form to delegate authorization to the underlying systems.
Phase 2 is the implementation of authorization first through capabilities at the service level; followed by the same identity-based authorization techniques from Phase 1.
3.2 Identity tokens - OpenID Connect¶
All identity tokens are OpenID Connect tokens. All OpenID connect tokens are JWT tokens. They are issued from CILogon in the exchange. In Phase 1 of our authentication system, we will pass around the OpenID connect tokens until the token issuer is set up as part of phase 2.
3.2.1 Claims¶
Minimally, the identity tokens issued by CILogon MUST include the following claims.
uidNumber: | The LSST UNIX UID. |
|---|---|
isMemberOf: | A list of JSON Objects with the objects composed
of a name key corresponding to UNIX group names; and id key corresponding to the UNIX GID
for the group name. |
3.3 Capability tokens - SciTokens¶
All capability tokens are based on SciTokens.
3.3.1 Claims¶
Minimally, the capability token issued by the token issuer MUST include the following claims:
sub: | The LSST User UNIX ID. Normally, SciTokens recommends against using this field for identification purposes. |
|---|---|
scope: | This is a list of space-separated capabilities. Capabilities are derived from the data and service classifications. This is similar to how GitHub allows scopes. |
3.4 Tokens vs. X.509¶
Fundamentally, identity tokens are roughly equivalent to X.509 certificates, though there are several advantages.
X.509 certificates are handled in Layer 4 in the OSI model, which typically leads to a more complicated setup of servers, clients, and applications.
OAuth tokens are handled in Layer 7 of the OSI model, which adds flexibility to configuration.
OAuth tokens can include additional claims that are useful for application developers.
Capabilities-based tokens allow issuance of tokens scoped accordingly to the services that a given application may require. A user may select only the capabilities needed for given use case, limiting access to sensitive information, such as query history. This is most important in lower trust environments, such as grid computing or shared university clusters.
4 Components¶
4.1 Clients¶
4.1.1 Portal¶
When a user first logs into the portal, they will be redirected to the token issuer. They may select
either NCSA as their Identity Provider or their home institution. CILogon executes the login,
ultimately returning information about who the user is at NCSA to the portal aspect through
CILogon’s OpenID Connect interface and the token’s sub claim. This provides the Portal aspect
with an access token and a refresh token.
Firefly is an OAuth 2.0 client and SHOULD use the refresh token to generate new access tokens. When
calls are made to DAX, the access token is passed as an OAuth 2.0 Bearer token in the HTTP
Authorization header, according to the OAuth 2.0 Specification:
Authorization: Bearer [TOKEN]
See also
4.1.2 Notebook¶
The Portal and the notebook MAY share some common session information about the user, including refresh tokens, to enable smooth transitions and interoperability between the two. How this is implemented is undefined.
Once a user is logged in to the Notebook access, a user in the Notebook aspect can be viewed as a special case of data access libraries, where we have some access to the user’s local environment, so we may be able to bootstrap an authentication mechanism on behalf of the user which ensures any necessary tokens are implicitly available in the user’s environment. For software developed by the LSST that may utilize the LSP API aspect services, such as the Butler, we will ensure those applications can be automatically configured based on some form of information in the user’s Notebook environment. Other third party software MAY be automatically configured, or they should be configurable in the same way as if a user was running on their local machine and not in an LSP instance.
4.1.3 TOPCAT¶
LSST will be working with the TOPCAT developers to find the best method of authentication. It’s expected that the embedded HTTP basic method will work to start. A slightly modified workflow from phase 1 for an application with identity token or phase 2 for for an application with a capability token is expected.
4.1.4 Data access libraries¶
We are targeting Astroquery an PyVO as primary libraries to be used within the Notebook environment. PyVO doesn’t currently implement any form of authentication; it’s expected that an identity token or capability token may be passed in the URL with the HTTP Basic Auth scheme.
Within the Notebook aspect, tokens MUST be available, either in an well-defined environment variables or as a file in a locations.
LSST SHOULD implement a token manager for Astroquery. For the notebook aspect, a method for initializing the token manager according the the stored token SHOULD be implemented.
4.2 Data Services¶
Todo
Not sure what to say here that’s not already said somewhere else
4.2.1 TAP¶
4.2.2 SIA¶
4.3 Token Manager¶
For phase 1, it’s desirable for clients to auto-configure, if possible, based on the identity token.
Todo
How do we get an ID token for Phase 1 for Applications?
In Phase 2, it’s desirable to limit the lifetime of the capabilities-based access tokens so that controls may be implemented at the token issuer to respond in a timely manner to changing conditions. In order to achieve that, the portal aspect is expected to implement a token manager which manages the lifecycle of the capability token using the refresh token received from the token issuer, as well as the token issuer.
Todo
How do we get capability tokens for Phase 2 for Applications?
4.4 Token Issuer¶
The token issuer is fundamentally a part of the IAM system. The token issuer’s primary purpose is to issue tokens with appropriate capabilities, based on a combination of information from LDAP, and user-selected scopes.
The token issuer is not needed for Phase 1.
In Phase 2, the token issuer will be presented with an identity token by a service, either the portal or some third-party application or library, and MUST issue a refresh token. The refresh token can be presented at any time to the token issuer for a capability token.
Todo
Service provided by data publisher Uses identity/refresh token to issue refresh/access token For our purposes, has a fixed list of scopes plus scopes derived from LDAP groups (no actual separate policy database needed) Limits scope to what client and user request/allow
4.5 Token Authorizer¶
All LSP services are responsible for validating tokens. For Phase 1, the portal and notebook are responsible for inspecting the token for any groups of interest, or delegating to a service, to control access to the service. The LSP API aspect is responsible for verifying the token received, as well as also inspecting the token for any groups of interest. Services in the LSP API aspect are also responsible for impersonation for the underlying systems.
In Phase 2, services in the LSP API aspect will rely on capabilities in the scope claim of the
capability token to limit access to the requisite service. It will then rely on impersonation for
finer-grained authorization.
4.6 Token Proxy¶
The LSP API Aspect MUST be able to make requests to other services. This requires relaying the appropriate tokens to the services. In order to satisfy a token acceptance guarantee, in the context of asynchronous and long-running requests, the LSP API Aspect MUST obtain, either through self-issuance or a request to the token issuer, a new token with a bounded lifetime which can be honored by the other LSP API aspect services.
Note
Safe HTTP methods, such as HEAD and GET requests SHOULD NOT need reissuance, as they SHOULD NOT take any other action other than simple retrieval.
The reissued token MAY alter the values of the following iss, exp, and iat claims. All
other claims MUST be included in the reissued token, unmodified.
Due to likely dependencies on a token issuer, the token proxy will be delayed until Phase 2.
5 Sequence Diagrams¶


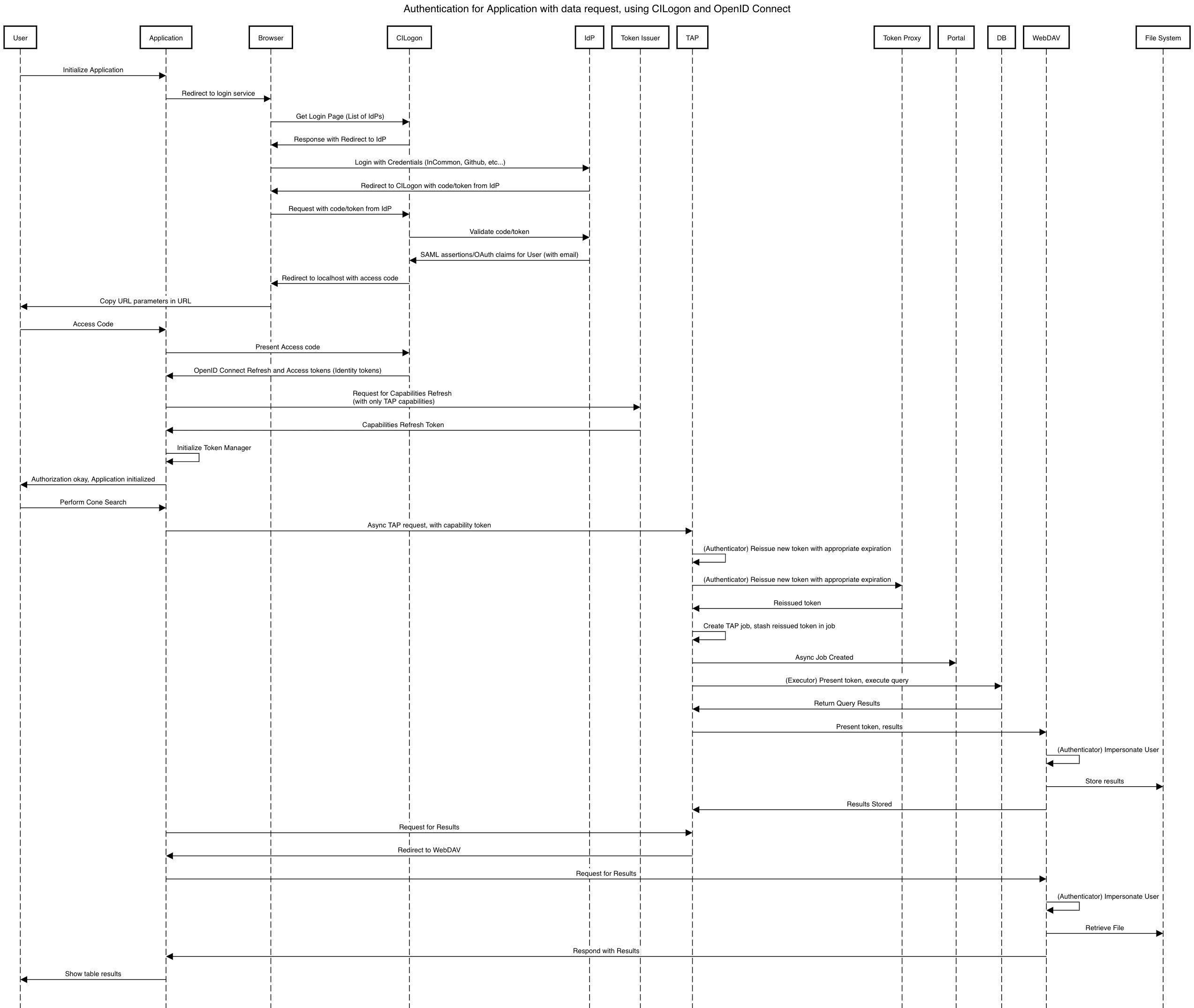



6 Interfaces¶
6.1 Client Token Manager to Token Issuer¶
Todo
I think this is already implemented in Portal and Notebook
6.2 Client Token Manager to Data Service Token Authorizer¶
Todo
Not sure if this is the same as Passing OAuth 2.0 Tokens
7 Appendix¶
- InCommon and eduPerson to verify attributes about scientists, when possible;
- CILogon to federate those identities and implement return identity data about users in the form of claims.
- OAuth 2.0 as the generic protocol to interface with CILogon. OpenID Connect is layered over the OAuth 2.0 protocol to required for an authentication implementation.
- OpenID Connect as the simple authentication layer on top of OAuth 2.0.
- JWT as the implementation for identity tokens. This is also required as a result of using OpenID Connect.
7.1 InCommon Federation¶
InCommon is an identity federation in the United States that provides a common framework for identity management and trust across member institutions. The InCommon Federation’s identity management is built on top of eduPerson attributes. The interface used to interact with the federated institutions is Shibboleth.
7.2 OAuth 2.0¶
OAuth2 is a framework that enables users to authorize applications to retrieve information, either in the form of a token or through the use of a token, about the user from an identity provider. An identity provider may be Google, Github or an institution. Typically, institutions themselves do not implement OAuth 2.0 interfaces, but do implement interfaces with Shibboleth and SAML.
OAuth 2.0 specifies how you may ask for information about a user. It also specifies a method, through tokens, which a service may use to request and validate information about the user.
7.2.1 Passing OAuth 2.0 Tokens¶
According to the OAuth 2.0 protocol, all tokens are transferred via the Authorization Header:
Authorization: Bearer [TOKEN]
This is the default, standard, and recommended way of passing ALL OAuth 2.0 tokens, whether it’s an OpenID Connect Identity token or a SciToken.
In some cases, existing clients of LSP services may exist that may not allow a user to send an arbitrary authorization header, or would need code to do so. It’s expected such a client may be configured to either provide an interface for HTTP Basic Authorization, or a user may manually populate a username and password into the URL.
For compatibility with such systems, some services in the LSP, most importantly the WebDAV service,
MAY accept tokens in the Authorization header according to HTTP Basic scheme, where the token is the
username and the password is x-oauth-basic, or empty.
For clients which do not allow specifying a username and a password directly, additional compatibility may be possible by manually constructing the URL with the token in it:
https://<token>:x-oath-basic@lsp.lsst.org/api
Warning
Care should be taken to always make the URL https, so tokens aren’t passed incorrectly.
7.3 OpenID Connect¶
OpenID Connect is an simple authentication layer on top of OAuth2. OpenID Connect specifies a small set of information about a user which may be used to authenticate a user using claims implemented according to the OAuth 2.0 specification.
7.4 CILogon¶
CILogon is a generic authentication proxy/clearing house for authentication providers from multiple services or institutions, especially institutions federated into the InCommon federation, as well as other services such as Github and Google. CILogon serves as a common endpoint for these various identity providers and translates their authentication mechanisms (OAuth 2.0, Shibboleth, OpenID Connect) mechanisms to a common authentication mechanism, often while also translating claims, when possible.
CILogon translates authentication information and user claims into OpenID Connect claims, layered on the OAuth 2.0 protocol. Using this, we typically know what institution a user is from, their email address, and whether or not they are faculty, staff, or a student. We may use this information to also map them to an NCSA user, provided that information has been previously captured, and potentially retrieve additional claims about that user, such as the groups they are a member of. Should we want additional claims beyond the subject of a token - claims such as group membership or capabilities, we will need to deploy a server which we can present a refresh token to that will provide us with those additional claims. We do not expect this implementation-specific needs to be included in CILogon.
7.5 JWT¶
A JSON Web Token (JWT) is a way of representing claims to as JSON, as well as information for validating those claims through the use of signatures (JWS) in the token, and a means of validating those signature (JWE/JWK) - all in the same token. Included in the JWT specification is also a way of encoding a token using Base64 in a way that’s friendly for the web.
For all LSST Applications, we will use RS256, an asymmetric algorithm, to sign the tokens.
We will be relying primarily on tokens generated by CILogon. In certain cases, the services MAY issue tokens that should be honored by other services. The primary use case of this is to ensure a request is completed by the system.
A whitelist of token issuers we trust MUST be maintained, and services that validate tokens MUST be configurable with that whitelist. Public keys used to validate tokens must be available on all token issuers, following to the JWK specification. Applications should cache the JWK for a given token issuer for at least 5 minutes and not more than 1 hour.
All Access Tokens will be based on JWT. Some access tokens may also include claims implemented according to the SciTokens specification.
See also
7.6 SciTokens¶
SciTokens is an implementation of capabilities-based
authorizations built as specific claims inside a JWT token.
Those claims are modeled as lists of capabilities; organized as colon-separated pairs of operations;
such as read, write, or execute, with arbitrary named resources. A named resource may be
a file path (e.g. read:/datasets/catalogs) or a more general resource (e.g.
read:mysql://server:3806/schema)
SciTokens recommends not using the subject (sub claim) for identity purposes. This implies that
SciTokens should not be used for authorizations based on identity.
SciTokens MUST be passed using one of the allowable methods defined for passing OAuth 2.0 Tokens.
A SciToken MUST come with a scope claim. The scope claim is a space-separated list of
capabilities. This is defined in RFC6749.
In accordance with the principle of least-privilege, a SciTokens issuer SHOULD also allow a user to attenuate or remove those capabilities with successive calls to the SciTokens issuer, trading an existing token for attenuated one. This may be especially useful with Grid computing, for example. It’s important to consider the lifetime of a token in these scenarios to determine what token may be required.
7.7 Token lifetimes¶
Access token lifetimes are expected to be short, typically on the order of several hours or less, but may last as long as 24 hours, depending on the issuer and use case. An exact number is not available.
Refresh tokens, which are used to acquire access tokens in the OAuth 2.0 protocol, can last longer. It’s expected a refresh token will last at least 24 hours and may last as long as a week. In some limited use cases, they may last longer.
7.7.1 Token Acceptance Guarantee¶
The LSP API aspect services intend to guarantee all requests received that a given API service received will succeed. To work with shorter access token lifetimes, the succeed. In order to guarantee this, the API services MUST issue a new token with the same claims which ONLY other API services will be configured to honor. The lifetime of this token is not specified, but it should the upper bound for the limit of time it takes to service a request, around 24 hours.
The LSP API aspect services SHOULD NOT issue new tokens from requests with DAX-issued tokens.